
|
Some Permutation Algorithms |
March, 2018
Despite the fact that there already are many web pages on this topic, and despite my admittedly limited expertise in this area, I would like to contribute something while attempting to avoid duplication of content.
It also occurred to me that some others might feel the same as I, in that many other
solutions are detailed in code that cannot be understood without a working knowledge
of the specific programming language being used. To that end, all code on this
page is presented in my beloved PowerBASIC, which is at least as readable as
most pseudo-code and is more easily interpreted than other syntaxes.
No Recursion: Although generatimg permutations is ideal
fodder for a recursive program, it is well-documented that recursion not
only is slower than non-recursive methods, but it can be prohibitively
resource-intensive as well; therefore, nothing recursive will be studied here.
Testing: The included algorithms have been analyzed for speed and efficiency. Every method produces results quickly enough to satisfy us mere mortals in actual practice, because we are not trying to launch a space shuttle or design a robot to be smarter than we are. Although I certainly do appreciate the quest for the 'perfect algorithm', choosing one compatible with individual programming needs is another matter.
About the code: All example algorithms process a string of consecutive digits starting with [1]; but unless it is otherwise specified, any integer values or character strings could be accommodated. The following format applies to all listed code:
|
· A() contains the string of items to be permuted.
· C() is utility storage. · Z() stores computed data as necessary. · R() is just for double-precision randoms. · TOT = number of items to be permuted. · PERMS = total permutations. · P and Q reference positions in the string of items. · CT is just for counting. · XX is a bit-array integer. · ODD(n) and EVEN(n) are macros that simulate the named functions. |
For the sake of readability, some routine setup such as the initialization of variables is not shown. It is assumed that you know that stuff already.

Okay. These algorithms purport to compile a listing of all the
different ways in which the items of a data set can be listed with regard
to the specific sequences. For example, there are six permutations of the digits
[1,2,3]: 123,132,213,231,312,321. Reproducing
that sequence, and in lexicographic (that is, sorted) order, should be relative
child's play for anyone who can count that high; but that is because the human brain
is vastly more capable than any computer.
One might guess that teaching a machine to sequence those digits would be equally
trivial, and simple solutions do exist. For a long time now, however,
mathematicians have been attempting to 'improve' upon the straightforward methods,
partly so as to reduce program run-time, and partly in order to get their
stuff published in some scientific journal or other. These efforts have
produced some amazing algorithms, as shall be seen.
Let's begin with an unlikely method that you will not find elsewhere.
I wrote it only to get myself started in this investigation, knowing that it would
work. The idea is simply to shuffle the string of four digits multiple times,
recording each new pattern as it is generated until all permutations have been
collected. This is accomplished using Ted's Tricky
Array-Mapping Technique.
— A Shuffle of Sorts —
SUB ArrayMatch 'Arguably primitive, but effective'===== TOT=4 'total items'===== DIM Z(1000000) AS LONG DIM A(1 TO TOT) AS LONG DIM R(1 TO TOT) AS DOUBLE FOR J=1 TO TOT: A(J)=J: NEXT 'initialize dataPERMS=1: FOR J=1 TO TOT: PERMS*=J: NEXT 'total perms = tot!CT=0 WHILE CT < PERMS FOR J=1 TO TOT: R(J)=RND: NEXT 'generate randomsARRAY SORT R(), TAGARRAY A() 'sort R() = shuffle A()K=0 FOR J=1 TO TOT K += 10^(TOT-J)*A(J) 'combine data to an integerNEXT IF Z(K)=0 THEN Z(K)=K: INCR CT 'flag integer if newWEND '(ct < perms) '---Output Z() here, ignoring empty cells END SUB '(arraymatch) |
Every shuffled string is logged by writing its value to the corresponding cell in
the array itself if that has not already been done. The CT variable
knows when all the PERMS finally have been generated. Then, scrolling
back through the array produces a list that is sorted in ascending order by
default! What a deal. Of course, this requires that array Z()
be dimensioned at least to the greatest integer permutation possible —
[4321] in this example. Also, the value of PERMS always must
be known in advance, in order to prevent an infinite search for new patterns.
Although any shuffling mechanism would suffice, the nifty TAGARRAY function provides a solution with an absolute minimum of program code.
Meanwhile, there should be a more efficient method than that for our purposes,
and there is. The following simple algorithm surely is the most straightforward
manner with which to permute the digits [1,2,3,4], because it
simulates the way that a human actually counts:
— Forloop Fiesta —
SUB FourLoops 'Just for digits 1-4FOR J=1 TO 4 FOR K=1 TO 4 IF K=J THEN ITERATE FOR 'digit already in useFOR L=1 TO 4 IF L=J OR L=K THEN ITERATE FOR ''FOR M=1 TO 4 IF M=J OR M=K OR M=L THEN ITERATE FOR '''---Output J,K,L,M here NEXT:NEXT:NEXT:NEXT END SUB '(fourloops) |
For every position in the string, digits are tried in ascending numeric order,
but are rejected if they match any digit already in use. Without interruption,
4×4×4×4, or 256 total loops would be run. With the
IF-THEN testing, just 168 loops are needed to generate the
24 permutations.
Rather than using all the IF-THEN functions to check on integer usage,
though, it occurred to me to try a Bit-Array to accomplish the same goal:
— Bits and Pieces —
SUB ForBITS 'Controls integer allocation with a bit-arrayFOR J=1 TO 4 BIT SET XX,J 'flag the counter-var as already usedFOR K=1 TO 4 IF BIT(XX,K) THEN ITERATE: ELSE BIT SET XX,K ''FOR L=1 TO 4 IF BIT(XX,L) THEN ITERATE: ELSE BIT SET XX,L ''FOR M=1 TO 4 IF BIT(XX,M) THEN ITERATE '---Output J,K,L,M here BIT RESET XX,M: NEXT M 'clear unwanted bit for the next loopBIT RESET XX,L: NEXT L ''BIT RESET XX,K: NEXT K ''BIT RESET XX,J: NEXT J ''END SUB '(forbits) |
Disappointingly, this routine runs more than three times slower than FourLoops. Frequently, the elegant bitwise functions perform best, but not this time.
In any case, the two prior algorithms are limited to handling a data set of specific length. In order to be truly worthwhile, the code must be more flexible. To that end, I restructured FourLoops to permute any number of consecutive integers:
— Homemade Handiwork —
SUB TedsPerm 'Output is lexicographic. 'Simulates TOT nested ForLoops.'===== TOT=6 'number of integers to permute'===== P=0 WHILE P < TOT INCR P DO '---Get One Permutation--- WHILE A(P)=TOT A(P)=0 DECR P: IF P=0 THEN EXIT SUB 'nothing more to doWEND 'INCR A(P) IF P > 1 THEN '---compare with prior a() for match--- Match=No FOR J=1 TO P-1 IF A(P)=A(J) THEN Match=Yes: EXIT FOR NEXT IF Match THEN ITERATE '(do) 'try another digitEND IF ' IF P < TOT THEN EXIT '(do) '---Output A() here LOOP '(get one perm) WEND '(p<tot) END SUB '(tedsperm) |
This routine iterates more than a million permutations per second on my
3.0-Ghz PC, but of course that isn't good enough for everyone.
— A Heap of Data —
In 1963, B.R. Heap came up with an ingenious method for generating permutations by means of calculated swaps of data items. Because no extra loops are involved, the routine was considered to be more or less as fast as possible. This is the famous Heap's Algorithm:
SUB Heap 'Output not in lexicographic orderREGISTER J AS LONG, N AS LONG 'greatly increases the speed'===== TOT=8 'total items'===== DIM A(0 TO TOT) AS LONG, C(0 TO TOT) AS LONG FOR J=0 TO TOT: A(J)=J+1: NEXT 'initialize data'---Output first A() here P=0 WHILE P < TOT IF C(P)< P THEN IF EVEN(P) THEN SWAP A(0),A(P): ELSE SWAP A(C(P)),A(P) '---Output A() here INCR C(P): P=0 ELSE C(P)=0: INCR P END IF '(c(p)< p) WEND '(p < tot) END SUB '(heap) |
If that code seems almost magical in its simplicity, that's because it is. Try to analyze its inner workings to see what I mean. It runs four times as fast as TedsPerm on four data items and nearly ten times as fast on eight items, when using the registered variable. You can read more about it here:
<wikipedia.org/HeapsAlgorithm>
— Even Faster —
Just after getting Heap to work, I discovered this newer one published by Phillip Paul Fuchs. It actually runs heaps faster than Heap. Perhaps you can figure out why.
SUB QuickPerm 'Output not in lexicographic order'====== TOT=10 'total items'====== DIM A(0 TO TOT) AS LONG DIM C(0 TO TOT) AS LONG FOR P=0 TO TOT: A(P)=P+1: C(P)=P: NEXT 'initialize arrays'---Output first A() here P=1 WHILE P < TOT DECR C(P) IF ODD(P) THEN J=C(P) ELSE J=0 SWAP A(J),A(P) '---Output A() here P=1 WHILE C(P)=0 C(P)=P: INCR P WEND WEND '(p < tot) END SUB '(quickperm) |
This variation is even better yet:
SUB QuickPermReversal 'Output not in lexicographic orderREGISTER P AS LONG '====== TOT=12 'total items'====== DIM A(0 TO TOT) AS LONG DIM C(0 TO TOT+1) AS LONG FOR J=0 TO TOT: A(J)=J+1: C(J)=J: NEXT 'initialize arrays'---Output first A() here P=1 WHILE P < TOT DECR C(P) J=0 WHILE J < P 'reverse remaining dataSWAP A(J),A(P) INCR J: DECR P WEND '---Output A() here P=1 WHILE C(P)=0 C(P)=P: INCR P WEND WEND '(p < tot) END SUB '(quickpermreversal) |
Kudos to anyone who can decipher what actually is happening in this code.
The rest can read all about the QuickPerms here:
<http://quickperm.org>
Here is a chart of the output of the last three algorithms, each permuting four digits:
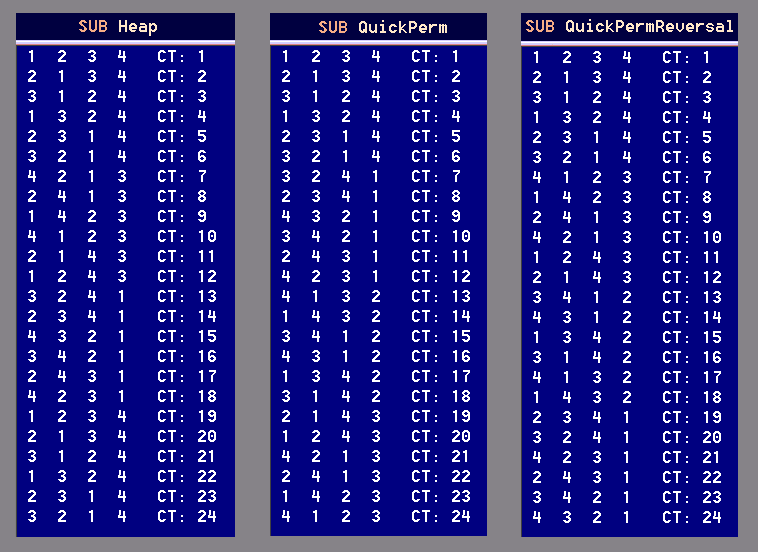
— A Golden Oldie —
Although many other algorithms are known, I'll round out this study with my favorite
method of them all, which was conceived in the 14th
Century by a lesser-known albeit gifted Indian mathematician named Narayana
Pandita. His insight is truly elegant in its simplicity, because once again
it essentially replicates the manner in which a human would generate such a listing
in real-time. Apparently no one had done such a thing previously.
Here it is, paraphrased for maximal readability:
|
· Find the rightmost P such that A(P)< A(P+1)
· Find the rightmost Q to the right of P such that A(Q)> A(P) · Swap A(P) with A(Q) · Reverse the elements to the right of P |
My requisite code is decidedly non-mysterious, and perhaps it could be improved:
SUB Pandita 'Output in lexicographic orderREGISTER J AS LONG, TOT AS LONG '===== TOT=5 'total items'===== DIM A(1 TO TOT) AS LONG FOR J=1 TO TOT: A(J)=J: NEXT 'initialize data'---Output first A() here DO '---[Get One Permutation per Loop]--- P=0 FOR J=1 TO TOT-1 'find rightmost P-value withIF A(J)< A(J+1) THEN P=J 'a greater value immediatelyNEXT 'to its right.IF P=0 THEN EXIT SUB 'finished! (5-4-3-2-1) 'FOR J=P+1 TO TOT 'find rightmost Q-val to theIF A(J)> A(P) THEN Q=J 'right of P that is greaterNEXT 'than P-val,SWAP A(P),A(Q) 'and swap them. 'FOR J=1 TO (TOT-P)\2 'reverse positions of allSWAP A(P+J),A(TOT+1-J) 'elements to the right of P.NEXT '---Output A() here LOOP '(get one perm) END SUB '(pandita) |
All that it took was for the man to spell out, in simplest terms, what actually happens during a lexicographic sequencing. What a concept.
CODE TWEAKING
A program designed for speed naturally should be coded so as to promote that objective. One aspect of QuickPerm, as presented, is not best (but see the Addendum):
| IF ODD(P) THEN J=C(P) ELSE J=0 SWAP A(J),A(P) |
Before continuing, however, perhaps it is time to reveal the details of the macros ODD() and EVEN(); for their usage is merely intended to make the algorithms a bit more readable:
ODD(P) -is the same as-P MOD(2) -and-EVEN(P) -is the same as-NOT (P MOD(2)) |
The QuickPerm author shows his student readers an elegant little
C++ function for assigning a value to J depending upon the status
of P, and invites them to improve upon it. Its BASIC equivalent
looks like this:
| J=C(P)*(P MOD(2)) SWAP A(J),A(P) |
Well, I don't know whether one can do better than to utilize the MOD()
function for this purpose; for I have tested various options. It is correct,
however, that the overall module can be improved. A better solution is to eliminate
both the multiplication and the redundant J-variable altogether:
| IF ODD(P) THEN SWAP A(C(P)),A(P) ELSE SWAP A(0),A(P) |
This adjustment enables the entire routine to run fully 3% faster, and that
increase is worth having. My Heap code is structured
in a similarly efficient manner, although it tests for EVEN() instead:
| IF EVEN(P) THEN SWAP A(0),A(P) ELSE SWAP A(C(P)),A(P) |
Oddly enough (sic), even though those two constructs seem functionally equivalent, the ODD() function runs slightly faster than EVEN() on my machine.
Much the same condition holds true for the data-reversal mechanism that I had set up for Pandita, as compared to the one in QuickPermReversal:
FOR J=1 TO (TOT-P)\2 'reverse positions of allSWAP A(P+J),A(TOT+1-J) 'elements to the right of P.NEXT -or-J=P+1: K=TOT WHILE J < K '<< this loop runs 33% faster! >>SWAP A(J),A(K) INCR J: DECR K WEND |
Although the Forloop design is more straightforward (as always), once again the logical comparison handily outperforms the math formulas. Pandita will be amended accordingly. Of course, anyone whose compiler features a REVERSE function might as well use it. My own IDE doesn't have one of those.
SPEED TESTS
Each algorithm was merely run through many complete loops while total time was
tracked — a million loops for just four integers, a thousand for eight
digits, etc., and just a single run for strings of ten or more items. No data
actually were output at all, because doing so would have consumed the same amount of time
irrespective of the other code. (FourLoops and
ForBits were augmented to accommodate eight integers.)
The following chart shows the results obtained after maximizing each algorithm as per previous discussion.
| TOTAL ITEMS: [permutations] |
4 [24] |
8 [40,320] |
10 [3,628.800] |
12 [479,001,600] |
13 [6,227,020,800] |
| ArrayMatch | 32.8/M (31.8-R) |
||||
| FourLoops | .70/M (.78-R) |
.0043 | |||
| ForBits | 2.36/M (2.27-R) |
.138 | |||
| TedsPerm | 3.54/M (3.21-R) |
.017 | 2.06 | 437 =1.1M/sec |
|
| Heap | .66/M (.54-R) |
.0010 (.0008-R) |
.093 (.075-R) |
17.2 (16.8-R) |
161 (131-R) =45M/sec |
| QuickPerm Reversal |
.48/M (.39-R) |
.0007 (.0006-R) |
.066 (.055-R) |
8.74 (7.30-R) =66M/sec |
113 (93.4-R) =67M/sec |
| Pandita | 1.0/M (.69-R) |
.0029 (.0019-R) |
.302 (.185-R) |
46.3 (26.8-R) =18M/sec |
641 (365-R) =17M/sec |
SO WHICH ALGORITHM IS BEST?
Not surprisingly, the answer is, "It depends". What is wanted from such code? Those dabbling in Artificial Intelligence naturally would demand the greatest possible speed, but the rest of us surely don't need that kind of performance.
Even if one is able to generate 67 million permutations per second using
QuickPermReversal, so what? I don't know about you; but my own
'life-clock' is not callibrated in millionths of a second, or even in
thousandths. My various programming projects would be happy with the speed
of any of the algorithms discussed.
Another important factor is functionality. Personally, I cannot conceive of a practical use for the likes of Heap or QuickPerm, because they do not produce data in a lexicographic sequence; so that limitation would seem to relegate them to the toybox of esoteric discussion. In contrast, the other algorithms do output in ascending order, and that's what my programs want. How about yours?
OTHER CONSIDERATIONS
Thus far, only data strings of unique items have been studied; but what if
there are some matching items? The values [1,2,3,3] would be a
simple example. In fact, some interesting features come to light.
Apparently, Heap and both QuickPerms treat
the two 3's as discrete elements such as 3(a) and 3(b), because
all permutations are duplicated during the calculations; moreover, any
additional matches would multiply the duplication-factor.
In contrast, Pandita and TedsPerm suppress
all duplication; but they have a limitation of their own. In order to generate
every permutation, the data string must be seeded starting with the
lexicographically minimal value. If the inital submitted order is [3,1,4,2],
for example, only the permutations 'greater' than that would be found; therefore,
the sequences from [1,2,3,4] through [3,1,2,4] would not
be generated. This could be a useful feature, though, I suppose.
That having been said, I must finish by pointing out that one of the algorithms does not suffer from either of those issues. That's right; despite your actual opinion of ArrayMatch, it does generate all permutations and does avoid duplication, irrespective of the original data sequence or values!
Did the tortoise beat the hare again?

ADDENDUM
In May of 2019, the creator of QuickPerm, having reviewed
my presumed 'fix' for his algorithm, wrote and graciously explained that the choice of
code was not an oversight; rather, it is dependent upon whether one employs a recursive
structure or an object-oriented one. (This also helps to explain why I use
PowerBASIC; I am not a fan of recursive code, despite its underlying elegance.)
In any case, thanks to Mr. Fuchs for clarifying this matter and for reading
my stuff.
